Introduction
Randomized Controlled Trials (RCTs) are considered the gold-standard of medical research. When RCTs are properly conducted, one can infer causation and not just correlation. In this post, I use open data from the medicaldata r package to reproduce some of the results of an RCT.
The paper we are going to reproduce is:
A Randomized Comparison between the Pentax AWS Video Laryngoscope and the Macintosh Laryngoscope in Morbidly Obese Patients, Anesthesia Analgesia 2011; 113: 1082-7.
We are going to reproduce Table 1, Figure 2, and Table 2 (Figure 1 is a photo of the Pentax AWS device).
A few important disclaimers
It is much easier to replicate the analysis when it is well explained and based on open data. Kudos to the authors of the paper and the authors of the medicaldata r package for their contribution to science and truth. None of this was possible without their generosity in sharing the data.
It is highly suggested to read the paper , the dataset description, and the codebook first and keep them accessible while reading this.
Mistakes happen all the time, even in this post.
Throughout this post, we will be using numerous r packages. I wish to thank all of their authors and contributors as well for making this analysis possible and much simpler.
It is outside the scope of this post to discuss choices in statistical analysis and presentation. Specifically, we will not discuss whether p-values or standardized differences should appear in a comparison of baseline characteristics in an RCT (Table 1), whether the statistical tests used are appropriate, and what is the ideal way to present missing values.
A few very important parts are missing in this post: exploratory data analysis, addressing missing values and potential outliers, unit-testing the code and results, and others. The code presented is highly focused on one part of the data analysis.
Data source
To download the data used for this analysis:
install.packages("medicaldata")
medicaldata::laryngoscope
Short description of the experimental design
Ninety nine obese patients (body mass index between 30 and 50 kg/m2) requiring orotracheal intubation for elective surgery were allocated randomly to tracheal intubation with either the Macintosh (using a #4 blade) or the Pentax AWS laryngoscope. Two experienced anesthesiologists served as laryngoscopists. Intubation success rate, time to intubation, ease of intubation, and occurrence of complications were recorded.
The study tested the hypothesis is that intubation with the Pentax AWS would be easier and faster than with a standard Macintosh #4 blade in obese patients.
Analysis
Packages
Most of the time, I use tidyverse as the basis of the workflow and skimr to quickly understand the dataset. There are many great packages for tables, but gtsummary by Daniel D. Sjoberg is definitely one of my favorites. The labelled package is a fantastic adjunct to add labels that appear in the tables. As mentioned above, all data comes from the wonderful medicaldata package by Peter D.R. Higgins. The packages survival and survminer are used to recreate the cumulative incidence curve and the Cox regression. The smd package is used specifically to calculate the standardized differences. The broom package, now also part of tidymodels simplifies extracting relevant results from different types of models.
Loading the data
The laryngoscope dataset appears in a data.frame. A first step would be to load it as a tibble for better printing properties (e.g., highlighting missing values, presenting variable types).
lar_raw <- as_tibble(medicaldata::laryngoscope)
Quick look
skim(lar_raw)
| Name | lar_raw |
| Number of rows | 99 |
| Number of columns | 22 |
| _______________________ | |
| Column type frequency: | |
| numeric | 22 |
| ________________________ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| age | 0 | 1.00 | 49.42 | 13.12 | 20.00 | 38.00 | 51.00 | 59.00 | 77 | ▃▆▇▇▂ |
| gender | 0 | 1.00 | 0.21 | 0.41 | 0.00 | 0.00 | 0.00 | 0.00 | 1 | ▇▁▁▁▂ |
| asa | 0 | 1.00 | 2.83 | 0.50 | 2.00 | 3.00 | 3.00 | 3.00 | 4 | ▂▁▇▁▁ |
| BMI | 2 | 0.98 | 41.92 | 5.23 | 30.92 | 37.97 | 42.00 | 44.76 | 61 | ▃▇▇▁▁ |
| Mallampati | 1 | 0.99 | 1.93 | 0.85 | 1.00 | 1.00 | 2.00 | 2.00 | 4 | ▇▇▁▅▁ |
| Randomization | 0 | 1.00 | 0.51 | 0.50 | 0.00 | 0.00 | 1.00 | 1.00 | 1 | ▇▁▁▁▇ |
| attempt1_time | 0 | 1.00 | 33.41 | 15.91 | 8.96 | 23.80 | 29.52 | 38.92 | 113 | ▇▆▁▁▁ |
| attempt1_S_F | 0 | 1.00 | 0.89 | 0.32 | 0.00 | 1.00 | 1.00 | 1.00 | 1 | ▁▁▁▁▇ |
| attempt2_time | 89 | 0.10 | 42.90 | 15.74 | 11.00 | 32.50 | 49.00 | 50.50 | 60 | ▂▃▁▇▆ |
| attempt2_assigned_method | 89 | 0.10 | 0.90 | 0.32 | 0.00 | 1.00 | 1.00 | 1.00 | 1 | ▁▁▁▁▇ |
| attempt2_S_F | 89 | 0.10 | 0.70 | 0.48 | 0.00 | 0.25 | 1.00 | 1.00 | 1 | ▃▁▁▁▇ |
| attempt3_time | 96 | 0.03 | 21.33 | 7.77 | 15.00 | 17.00 | 19.00 | 24.50 | 30 | ▇▇▁▁▇ |
| attempt3_assigned_method | 96 | 0.03 | 0.33 | 0.58 | 0.00 | 0.00 | 0.00 | 0.50 | 1 | ▇▁▁▁▃ |
| attempt3_S_F | 96 | 0.03 | 1.00 | 0.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1 | ▁▁▇▁▁ |
| attempts | 0 | 1.00 | 1.13 | 0.42 | 1.00 | 1.00 | 1.00 | 1.00 | 3 | ▇▁▁▁▁ |
| failures | 0 | 1.00 | 0.13 | 0.42 | 0.00 | 0.00 | 0.00 | 0.00 | 2 | ▇▁▁▁▁ |
| total_intubation_time | 0 | 1.00 | 37.48 | 21.02 | 8.96 | 24.37 | 31.00 | 45.37 | 100 | ▆▇▂▁▁ |
| intubation_overall_S_F | 0 | 1.00 | 0.96 | 0.20 | 0.00 | 1.00 | 1.00 | 1.00 | 1 | ▁▁▁▁▇ |
| bleeding | 0 | 1.00 | 0.02 | 0.14 | 0.00 | 0.00 | 0.00 | 0.00 | 1 | ▇▁▁▁▁ |
| ease | 0 | 1.00 | 45.22 | 30.47 | 0.00 | 15.00 | 40.00 | 70.00 | 100 | ▇▅▅▃▃ |
| sore_throat | 1 | 0.99 | 0.47 | 0.78 | 0.00 | 0.00 | 0.00 | 1.00 | 3 | ▇▂▁▁▁ |
| view | 0 | 1.00 | 0.82 | 0.39 | 0.00 | 1.00 | 1.00 | 1.00 | 1 | ▂▁▁▁▇ |
Some relevant issues:
Missing values in the
BMI,Mallampati,sore_throatcolumns.All variables are defined as numeric, even those that are probably better represented as factors or ordered factors.
Processing
The function as.roman is used to translate numbers to Roman numerals, set_variable_labels is a simple way to assign labels once that would appear in all tables created by gtsummary later.
lar <- lar_raw %>%
mutate(male = gender == 1,
laryngoscope = if_else(
Randomization == 0,
"MacIntosh",
"Pentax AWS") %>%
fct_rev(),
asa_roman = factor(as.character(as.roman(asa))),
sore_throat_fct = factor(sore_throat, 0:3, c("None", "Mild", "Moderate", "Severe"), ordered = T),
Mallampati_fct = factor(Mallampati, ordered = T)
) %>%
set_variable_labels(
age = "Age, years",
male = "Males",
BMI = "Body mass index, kg/m^2",
asa_roman = "ASA physical status",
Mallampati_fct = "Mallampati score",
total_intubation_time = "Intubation time, s",
ease = "Ease of intubation",
attempt1_S_F = "Successful intubation, first attempt",
intubation_overall_S_F = "Overall successful intubation",
attempts = "No. of intubation attempts",
view = "Cormack-Lehane grade (good)",
bleeding = "Bleeding (trace)",
sore_throat_fct = "Sore throat"
)
SMD function
We define a function get_smd to utilize the smd::smd function and adapt it to be used in gtsummary tables. For more information on how to do this, see this section or type ?tests.
get_smd <- function(data, variable, by, ...) {
smd::smd(x = data[[variable]], g = data[[by]], na.rm = TRUE)["estimate"]
}
Table 1
The function tbl_summary is used to create descriptive tables and is highly customizable. The presented variables can also be chosen with the argument include =, but sometimes it easier to choose them with select.
The syntax may be difficult to understand at first, but with some practice it gives a lot of flexibility. Especially, the selection helpers (e.g., all_continuous() and all_categorical()) simplify complex editing of the table in a reproducible way.
Regarding the results, note that the mean BMI in the Pentax AWS group is slightly different that in the article. Assuming we have the same dataset, this is likely a typing error – another reason to use R ± R Markdown to produce the publication-ready results. Also, two missing values of BMI are not mentioned in the table (unlike the one patient with missing Mallampati score), but can be seen clearly in the default tbl_summary output.
lar %>%
select(laryngoscope, age, male, BMI, asa_roman, Mallampati_fct) %>%
tbl_summary(by = "laryngoscope",
statistic = list(all_continuous() ~ "{mean} ({sd})")) %>%
add_stat(fns = list(
all_continuous() ~ "get_smd",
all_categorical() ~ "get_smd")
) %>%
modify_header(estimate ~ "Standardized difference") %>%
modify_fmt_fun(update = estimate ~ function(x){scales::number(x, accuracy = 0.01)})
| Characteristic | Pentax AWS, N = 501 | MacIntosh, N = 491 | Standardized difference |
|---|---|---|---|
| Age, years | 50 (12) | 49 (14) | 0.14 |
| Males | 11 (22%) | 10 (20%) | 0.04 |
| Body mass index, kg/m^2 | 41.4 (4.4) | 42.5 (5.9) | -0.21 |
| Unknown | 2 | 0 | |
| ASA physical status | 0.41 | ||
| II | 15 (30%) | 7 (14%) | |
| III | 32 (64%) | 40 (82%) | |
| IV | 3 (6.0%) | 2 (4.1%) | |
| Mallampati score | 0.57 | ||
| 1 | 21 (42%) | 14 (29%) | |
| 2 | 18 (36%) | 21 (44%) | |
| 3 | 7 (14%) | 13 (27%) | |
| 4 | 4 (8.0%) | 0 (0%) | |
| Unknown | 0 | 1 | |
|
1
Mean (SD); n (%)
|
|||
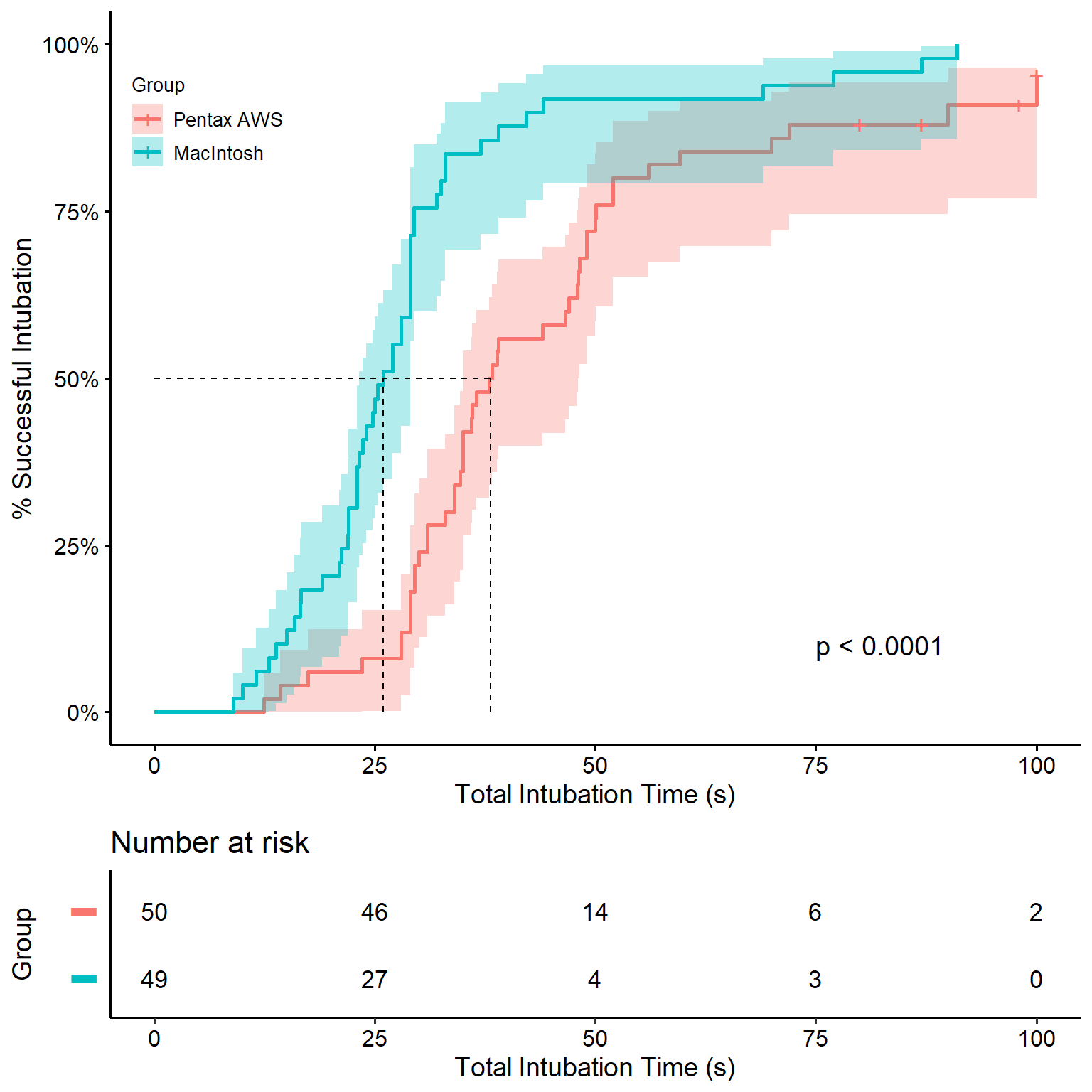
Time to success (Figure 2)
To reproduce the figure, we use the ggsurvplot function from survminer. The strata names can be set inside the function using legend.labs = and a character vector. However, this could easily lead to a mistake in labeling without producing an error nor warning. Therefore, it is recommended to adjust the labels programmatically.
cum_inc <- surv_fit(Surv(total_intubation_time, intubation_overall_S_F) ~ laryngoscope, data = lar)
names(cum_inc$strata) <- names(cum_inc$strata) %>% str_remove("laryngoscope=")
cum_inc %>%
ggsurvplot(fun = "event", conf.int = T, pval = T,
risk.table = T, surv.median.line = "hv",
xlab = "Total Intubation Time (s)",
ylab = "% Successful Intubation",
surv.scale = "percent",
legend.title = "Group",
tables.y.text = F,
legend = c(0.1, 0.85),
pval.coord = c(75, 0.1)
)
Treatment effect functions
Table 2 is a regular cross table, very similar to Table 1, but also has Treatment effect calculated in different ways for each row. This poses a challenge as many of the functions needed for treatment effect are not built-in to gtsummary. However, these could easily be defined - either as general functions or as the results of a calculation.
Fisher’s exact example
For example, one could calculate the Fisher’s exact between the two columns. Notice that the add_p function does have a "fisher.test" option, but since we are calculating many different types of treatment effects using add_difference, I calculate it here separately.
get_fe <- function(data, variable, by, ...) {
fisher.test(data[[variable]], data[[by]]) %>%
tidy() %>%
mutate(estimate = NA_real_,
conf.low = NA_real_,
conf.high = NA_real_,
)
}
Hazard ratio example
For the Cox regression, I use a different approach where the function returns just a one-row tibble with the results regardless of the input.
get_hr <- function(data, variable, by, ...) {
data <- lar %>% mutate(laryngoscope = fct_rev(laryngoscope))
coxph(Surv(total_intubation_time, intubation_overall_S_F) ~
laryngoscope + asa_roman + Mallampati_fct,
data = data) %>%
tidy(exponentiate = T, conf.int = T) %>%
slice(1) %>%
mutate(method = "Cox regression")
}
Some more examples
get_ancova <- function(data, variable, by, ...) {
mean_diff <- t.test(data[[variable]] ~ data[[by]]) %>%
tidy() %>%
select(estimate, conf.low, conf.high)
p_val <- aov(ease ~ laryngoscope + asa_roman + Mallampati_fct, data = lar) %>%
tidy(conf.int = T) %>%
slice(1)
bind_cols(mean_diff, p_val) %>%
mutate(method = "ANCOVA")
}
get_glm <- function(data, variable, by, ...) {
data <- lar %>% mutate(laryngoscope = fct_rev(laryngoscope))
data$outcome <- data[[variable]]
data <- data %>% select(outcome, laryngoscope, asa_roman, Mallampati_fct) %>%
na.omit()
glm(outcome ~ laryngoscope +
asa_roman + Mallampati_fct,
family = "binomial",
data = data
) %>%
tidy(exponentiate = T, conf.int = T) %>%
slice(2) %>%
mutate(method = "Logistic regression")
}
Table 2
Note that it is possible to pass the tbl_summary the full tibble and to select variables for presentation using the include = argument. This allows the use of adj.vars = with a character vector of variables used for adjustment only. For example, with add_difference(test = list(all_continuous() ~ "ancova").
On purpose, we did not include here all treatment effects. I highly suggest you try writing functions for them yourself.
lar %>%
select(laryngoscope, total_intubation_time,
ease, attempt1_S_F,
intubation_overall_S_F, attempts, view, bleeding, sore_throat_fct
) %>%
tbl_summary(by = "laryngoscope", statistic = list(ease ~ "{mean} ({sd})")
) %>%
add_difference(test = list(
total_intubation_time ~ "get_hr",
ease ~ "get_ancova",
intubation_overall_S_F ~ "get_fe",
bleeding ~ "get_fe",
attempt1_S_F ~ "get_glm",
view ~ "get_glm"
))
| Characteristic | Pentax AWS, N = 501 | MacIntosh, N = 491 | Difference2 | 95% CI2,3 | p-value2 |
|---|---|---|---|---|---|
| Intubation time, s | 38 (31, 50) | 26 (22, 29) | 0.35 | 0.21, 0.56 | <0.001 |
| Ease of intubation | 52 (31) | 38 (28) | 14 | 2.0, 26 | 0.023 |
| Successful intubation, first attempt | 43 (86%) | 45 (92%) | 64% | 14%, 261% | 0.5 |
| Overall successful intubation | 46 (92%) | 49 (100%) | 0.12 | ||
| No. of intubation attempts | 0.24 | -0.16, 0.63 | |||
| 1 | 44 (88%) | 45 (92%) | |||
| 2 | 3 (6.0%) | 4 (8.2%) | |||
| 3 | 3 (6.0%) | 0 (0%) | |||
| Cormack-Lehane grade (good) | 43 (86%) | 38 (78%) | 210% | 65%, 763% | 0.2 |
| Bleeding (trace) | 2 (4.0%) | 0 (0%) | 0.5 | ||
| Sore throat | 0.23 | -0.17, 0.63 | |||
| None | 34 (68%) | 32 (67%) | |||
| Mild | 9 (18%) | 12 (25%) | |||
| Moderate | 5 (10%) | 3 (6.2%) | |||
| Severe | 2 (4.0%) | 1 (2.1%) | |||
| Unknown | 0 | 1 | |||
|
1
Median (IQR); Mean (SD); n (%)
2
Cox regression; ANCOVA; Logistic regression; Fisher's Exact Test for Count Data; Standardized Mean Difference
3
CI = Confidence Interval
|
|||||
Lessons learned
General lessons
- Reproducing an analysis of a published study, where you have the same data and the finished product, is a great exercise that forces you to understand the importance of the methods section, step out of the box of the methods you regularly use, and get to know new arguments and functions.
Data analysis lessons
- Script to publication-ready tables / plots are likely to minimize typing errors.
- Whenever a good package with a good tested function exists, it is usually best practice to use it instead of writing a new untested function. If necessary, a function wrapper is better than writing for scratch. This could have its disadvantages, especially when packages are updated. Therefore, it is important to also keep the session information.
- Much of the code presented can be improved, shortened, or simplified. Although most of the time correlated, sometimes coding write and getting things done are a trade-off.
R related lessons
- Labeling a
ggplot, or in this case aggsurvplot, for commiunication can lead to unintentional errors. One way to avoid it is to produce the labels programmatically instead of manually (see Figure 2). skimr::skim()is extremely valuable in exposing datasets problem fast.labelled::set_variable_labelsallows assigning labels once to be used in multiple tables.